Shark简介
Shark[1]是UC Berkeley AMPLAB开源的一款数据仓库产品,它完全兼容Hive的HQL语法,但与Hive不同的是,Hive的计算框架采用MapReduce,而Shark采用Spark(也是AMPLAB开源的分布式计算框架,充分利用内存,适合于迭代计算,官方宣称性能比MapReduce好100倍)。所以Hive是SQL on MapReduce,而Shark是Hive on Spark。以下是官方简介:
Shark is a large-scale data warehouse system for Spark designed to be compatible with Apache Hive. It can answer Hive QL queries up to 100 times faster than Hive without modification to the existing data nor queries. Shark supports Hive’s query language, metastore, serialization formats, and user-defined functions.
简要总结下Shark的特性[2]:
- builds on Spark
- scales out & fault-tolerant
- supports low-latency, interactive queries through in-memory compution
- support both SQL and complex analytics such as machine learning
- is compatible with Apache Hive (storage, serde, UDF, types, metadata)
Shark的架构
Shark是架构在Hive之上的,它复用了Hive的架构并增加了一些特性,所以Shark的整个代码量很小,大约1万多行。
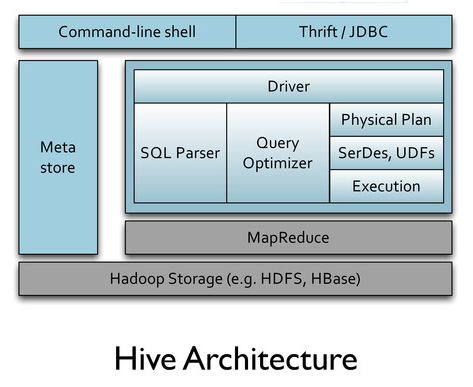
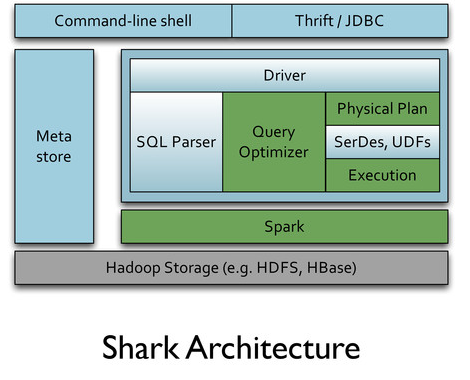
从上两张图中可以看出,Shark复用了Hive的大部分组件,包括:
- SQL Parser: Shark完全兼容Hive的HQL语法
- metastore:Shark采用和Hive一样的meta信息,Hive里创建的表用Shark可无缝访问
- SerDe: Shark的序列化机制以及数据类型与Hive完全一致
- UDF: Shark可重用Hive里的所有UDF
- Driver: Shark在Hive的CliDriver基础上进行了一个封装,生成一个SharkCliDriver,这是shark命令的入口
- ThriftServer:Shark在Hive的ThriftServer(支持JDBC/ODBC)基础上,做了一个封装,生成了一个SharkServer,也提供JDBC/ODBC服务。
Shark的使用技巧
- 选择运行模式: 在Shark的CliDriver里,可以通过set shark.exec.mode=shark/hive来选择用shark还是hive来执行HQL
创建缓存表以提高查询速度: 可以创建缓存表将数据cache在内存中,以提高查询速度。以下两种DDL语法均可以:
- CREATE TABLE wiki_small_in_mem TBLPROPERTIES (“shark.cache” = “true”) AS SELECT * FROM wiki;
- CREATE TABLE wiki_cached AS SELECT * FROM wiki;