概述
上一节简单介绍了如何搭建Spark的本地开发环境,并示例了一个SparkHelloWorld project。本节详细介绍Spark的Scala API,并介绍Spark编程的高级特性。
Spark程序其实是一个包含main函数的driver程序,它通知集群对RDD进行一系列的并行操作。RDD是Spark的核心,它分片分布在集群的各个节点上,以便进行并行操作。RDD通过hdfs或其他hadoop支持的文件系统创建,或者从其他已存在的RDD转换而来。用户可以对RDD进行一些列的动作操作,比如count,reduce等。也可以转变RDD的存储状态,比如,cache将RDD缓存在内存中,save将RDD保存到文件系统。RDD自身是fault-tolerant,当节点宕机时通过血统来recovery。
Spark编程的主要工作其实就是创建RDD,转换RDD,对RDD进行相应的动作。同时Spark提供了另外一个抽象:共享变量。用户的driver程序可以将方法中定义的变量分发给Spark集群各个节点以便与driver共享并进行并行操作。目前有两种实现:broadcast variables(将数据cache在集群的各个节点的内存中,实现类似于MapReduce中DistributedCache的功能来加快数据访问)和accumulators(只实现了一个added方法,用以实现计数器功能)
下面我们进行详细介绍,并给出一些例子。一个典型的Spark用户程序的主要包含以下步骤:
- 初始化SparkContext
- 创建RDD
- 对RDD进行一系列Operation
- 利用共享变量实现某些高级特性
初始化SparkContext
- 将spark-core以及其依赖的jar包加入CLASSPATH(可以通过sbt或者maven)。详见上节介绍,在此不赘述。
import Spark相关的class或变量。在driver的用户程序中加入以下代码:
import spark.SparkContext import spark.SparkContext._创建SparkContext对象
val sc = new SparkContext(master, appName, [sparkHome], [jars])
第一个参数指定Spark集群的Master URL,可以为以下几种:
| Master URL | 含义 | |
|---|---|---|
| local | 采用一个worker线程本地运行 | | |
| local[K] | 采用K个线程本地运行 | | |
| spark://HOST:PORT | 连接到Spark Standalone集群的Master,HOST是Master的IP或hostname,端口默认7077 | | |
| mesos://HOST:PORT | 连接到Mesos集群,HOST是Mesos master的IP或hostname,端口默认5050 | |
第二个参数指定该App程序的名字 第三个参数和第四个参数,当该App需要跑在集群模式下时必须指定。sparkHome指定在worker节点上Spark的安装路径;jars指定当前App程序所依赖的jar包的列表。可以通过sbt-assembly将该App与其依赖jar包打成一个jar。
Note: spark-shell启动的时候已经初始化好SparkContext叫做sc,可以直接使用。用户可以通过系统变量来自定义sc,如以下例子利用本地的4个core运行,将code.jar加入CLASSPATH:
$ MASTER=local[4] ADD_JARS=code.jar ./spark-shell
创建RDD
有两种方式创建RDD:
将已存在的Scala Collection Object parallelized化:这样这个Scala Collection的元素就会copy形成一个RDD就可以对它进行并行操作,例如下例对Array进行并行化:
val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data)Note:默认Spark会根据集群情况自动分片,用户可以通过指定第二个参数来手工分片,如将data手工分为10片:
val distData = sc.parallelize(data,10)从Hadoop创建: Spark可以从Hadoop支持的文件系统或其他存储系统(本地文件系统,HDFS,KFS,S3,HBase,etc)读取文件创建RDD。Spark支持TextFile, SequenceFile以及其他所有InputFormat。
sc.textFile("file.txt") sc.textFile("directory/*.txt") sc.textFile("hdfs://namenode:port/path/textfile") sc.sequenceFile("hdfs://namenode:port/path/sequencefile",Int,String) sc.hadoopRDD(conf, inputFormatClass, keyClass, valueClass)
Note: 以上方法最后一个参数可以调节文件的分片数。默认为一个block一个slice,用户可以上调这个参数来获得更大的slice size。
RDD Operations
RDD支持两类Operation:transformation(对以存在的RDD进行转换生成另一个RDD)和action(对RDD进行聚集操作)
Transformation:
Spark支持的transformation如下表:
Transformation Meaning map(func) Return a new distributed dataset formed by passing each element of the source through a function func. filter(func) Return a new dataset formed by selecting those elements of the source on which func returns true. flatMap(func) Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). mapPartitions(func) Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator[T] => Iterator[U] when running on an RDD of type T. mapPartitionsWithSplit(func) Similar to mapPartitions, but also provides func with an integer value representing the index of the split, so func must be of type (Int, Iterator[T]) => Iterator[U] when running on an RDD of type T. sample(withReplacement, fraction, seed) Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed. union(otherDataset) Return a new dataset that contains the union of the elements in the source dataset and the argument. distinct([numTasks])) Return a new dataset that contains the distinct elements of the source dataset. groupByKey([numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, Seq[V]) pairs.
Note: By default, this uses only 8 parallel tasks to do the grouping. You can pass an optionalnumTasksargument to set a different number of tasks.reduceByKey(func, [numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument.sortByKey([ascending], [numTasks]) When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the boolean ascendingargument.join(otherDataset, [numTasks]) When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. cogroup(otherDataset, [numTasks]) When called on datasets of type (K, V) and (K, W), returns a dataset of (K, Seq[V], Seq[W]) tuples. This operation is also called groupWith.cartesian(otherDataset) When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). Actions:
Spark支持的action类型如下表:
Action Meaning reduce(func) Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. collect() Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. count() Return the number of elements in the dataset. first() Return the first element of the dataset (similar to take(1)). take(n) Return an array with the first n elements of the dataset. Note that this is currently not executed in parallel. Instead, the driver program computes all the elements. takeSample(withReplacement, num, seed) Return an array with a random sample of num elements of the dataset, with or without replacement, using the given random number generator seed. saveAsTextFile(path) Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file. saveAsSequenceFile(path) Write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. This is only available on RDDs of key-value pairs that either implement Hadoop’s Writable interface or are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, etc). countByKey() Only available on RDDs of type (K, V). Returns a Mapof (K, Int) pairs with the count of each key.foreach(func) Run a function func on each element of the dataset. This is usually done for side effects such as updating an accumulator variable (see below) or interacting with external storage systems. Persist or Cache
RDD可以通过persist()或者cache()方法缓存在内存中,以便后续操作重用来使得查询更快。这是Spark更好的支持interative算法和interactive Job的关键所在。
persist方法可以传入一个参数供用户自定义存储级别,默认为MEMORY_ONLY,即存储在内存中。cache()方法是将RDD缓存在内存中的便捷方法。Spark支持的存储级别如下表:
Storage Level Meaning MEMORY_ONLY Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, some partitions will not be cached and will be recomputed on the fly each time they’re needed. This is the default level. MEMORY_AND_DISK Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, store the partitions that don’t fit on disk, and read them from there when they’re needed. MEMORY_ONLY_SER Store RDD as serialized Java objects (one byte array per partition). This is generally more space-efficient than deserialized objects, especially when using a fast serializer, but more CPU-intensive to read. MEMORY_AND_DISK_SER Similar to MEMORY_ONLY_SER, but spill partitions that don’t fit in memory to disk instead of recomputing them on the fly each time they’re needed. DISK_ONLY Store the RDD partitions only on disk. MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. Same as the levels above, but replicate each partition on two cluster nodes.
共享变量
正常情况下,当一个方法传给Spark Operation在远程节点上执行时,需要复制方法里的变量传输给各个节点,这些变量在远程节点上并不会更新然后又传回driver程序。为了支持通用情况,这种在task之间共享变量的方式是非常低效的。
然而,Spark支持两种限定类型的共享变量:broadcast变量和accumulator。
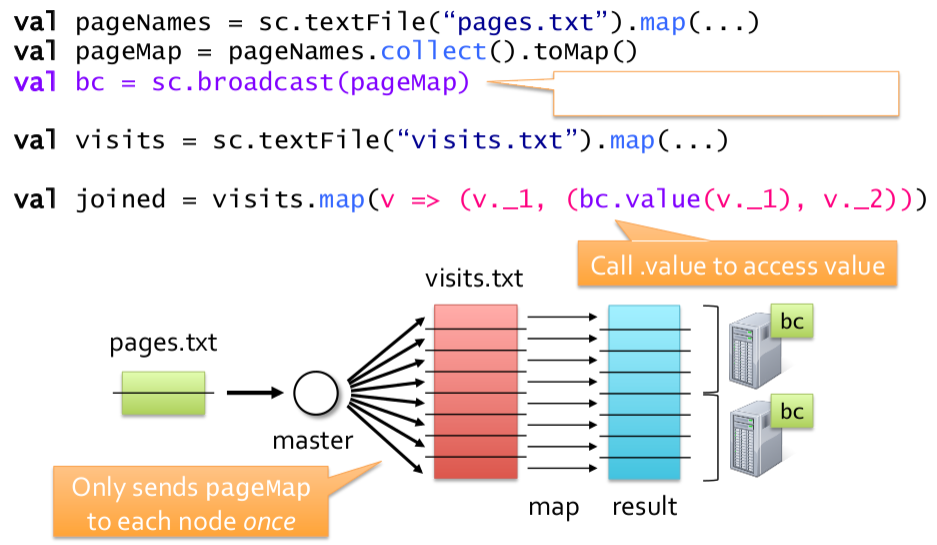
- broadcast变量: broadcast变量允许用户程序在每个节点上维持一个只读的变量在内存中,而不是在task间来回复制。可以利用broadcast变量将一个小数据集分发并维持到各个节点,实现MapJoin。
- accumulator: accumulator用来实现类似与MapReduce计数器的功能,它只有累加方法。
